AMD Ryzen 5000 series based on the new Zen 3 architecture is finally released. AMD Zen 2’s Ryzen has always been the only weak single-core and game performance and that is finally no longer its shortcoming in the upgraded AMD Zen 3 architecture. It has achieved a surpassing Intel in one fell swoop, and it was done under the premise of maintaining the 7nm process completely unchanged. The newly designed Zen 3 architecture can be said to be indispensable, and this is also the biggest change since the birth of Zen.

Of course, processor architecture design is an extremely advanced knowledge and we, honestly can’t talk about it in depth and professionalism, just talk about something that is more superficial and easy to understand, and see how such a sky-defying performance leap comes from.
First of all, you must have goals in everything you do, especially when designing a processor architecture. Zen 3 has three goals:
The first is to improve the single-thread performance. The technical term is IPC – instructions per clock cycle. After all, the previous generations including AMD Zen 2 have been pursuing multi-core performance. It is time to increase the single-core performance to a sufficient level, otherwise it will always be considered inferior to Intel’s offerings.
The second is to unify the core and cache while maintaining the 8-core CCD module to improve the efficiency of mutual communication and reduce latency.
The third is to continue to improve the energy efficiency ratio, and the power consumption cannot be out of control while the performance is improved.
To this end, the Zen 3 architecture has refurbished all modules, including front-end, prefetching, decoding, execution, integer, floating point, loading, storage, caching, etc., each link is completely new.
First, Zen 3 designed a state-of-the-art branch predictor. After that, there are two channels to send instructions to the queue and then dispatch them. One is an 8-way associated 32KB L1 instruction cache and x86 decoder, and the other is 4K. Operational cache of instructions (Op-cache).
The limitation of the x86 decoder is that each clock cycle can only process up to 4 instructions, but if it is a familiar instruction, it can be placed in the operation cache, and 8 instructions can be processed per cycle. The combination of the two can greatly improve the efficiency of instruction distribution. Compared to Zen 2, it is directly up a notch.
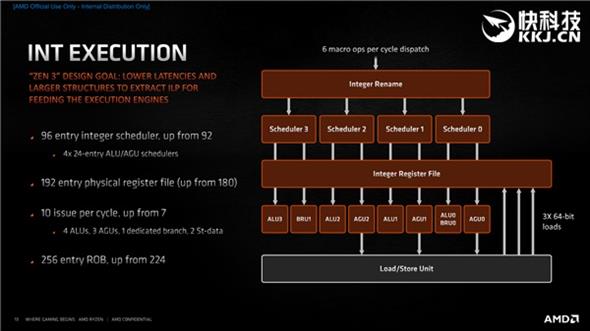
After the instruction is dispatched, it comes to the execution engine stage, which is divided into two parts: integer and floating point, and 6 instructions can be dispatched to them every clock cycle.
Among them, there are still 4 integer units, but they are more dispersed, and a separate branch and data storage unit is added to improve throughput, and 3 addresses can be generated per clock cycle.
Floating point is divided into six pipelines to further improve throughput and efficiency.
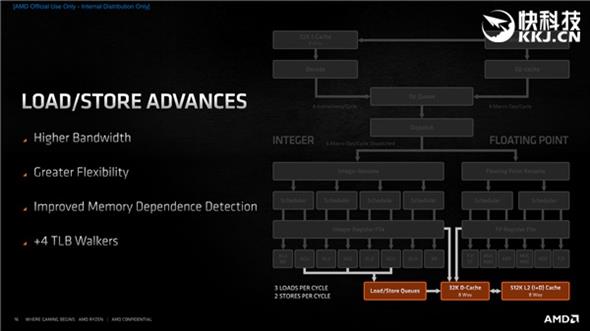
In terms of memory, 3 loads can be executed per clock cycle, or 1 load plus 2 storage, which again improves throughput and can handle different workloads more flexibly.
Just say that Zen 3 may not feel anything, then compare Zen 2, if there are too many changes, it is still the most important thing.
On the front end, there are mainly L1 BTB with doubled capacity, larger branch predictor bandwidth, faster prediction error recovery, faster operation cache pickup, more refined operation cache pipeline switching, and so on.

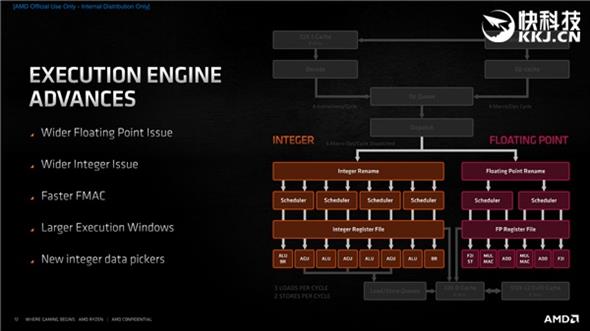
In terms of execution engine, there are mainly independent branches and data storage units, larger integer windows, lower specific integer/floating point instruction latency, 6-width pickup and distribution, wider floating point dispatch, and faster floating point FMAC (Multiplication accumulator), etc.
In terms of load/store, there are mainly higher load bandwidth (2 changes to 3), higher storage bandwidth (1 change to 2), more flexible load/store instructions, and better memory dependency detection, and many more.
The above are the changes in some key indicators of the core and cache of the Zen, Zen 2, and Zen 3 three-generation architectures. At first glance, Zen 3 seems to be less dynamic than Zen 2, but first, these numbers cannot fully reflect deeper changes, and second, Zen 3 has more breakthroughs in key indicators, such as the distribution width jumped from 10/11 to 16. Implementation efficiency can be improved by more than a little bit.
It is based on these improvements that the IPC of the Zen 3 architecture has increased by as much as 19%, from the combined contributions of the front-end, load/store, execution engine, cache prefetch, micro-operation cache, branch prediction, etc.
It’s simple to say, Zen 3 and Zen 2 architectures are fixed at 8 cores and 4GHz frequency, and then compare the performance changes of different applications, and finally integrate them.
The increase rate of different workloads is of course not the same. The biggest change is Ryzen’s previous weak online games. Chicken, LOL, and CSGO have increased by as much as 35-39%, plus the frequency increase, and everyone will see it. Ryzen 5000 has undergone earth-shaking changes in online games.
In fact, the increase rate is more than 19% of the average level, basically it is the game, and because of this, the Ryzen 5000 has taken the last position of Intel in game performance, and is qualified to say that it is the best game processor. Device.
The relatively small improvement is some benchmark projects and some games that are difficult to optimize deeply, especially single-threaded performance, such as POV-Ray 9%, CPU-Z 12%, CineBench R20 13%, CineBench R15 18%, but even In this way, everyone has seen a very obvious actual performance improvement, which is much more than the change of conscience of up to 5% at a time of some generations of Core.
In the front-end part, Zen 3 has built a faster branch predictor that can process more instructions in each clock cycle. At the same time, it can switch between the operation cache and the instruction cache faster, and it can cope with different workloads more flexibly and efficiently.
Of course, branch prediction cannot be 100% accurate. It is probabilistic. Sometimes the prediction is wrong. The key at this time is whether it can recover quickly. Zen 3 greatly reduces the delay at this time and can quickly return to the right track. Branch prediction The accuracy has also been improved.
In the picking and decoding part, you can see more details of the branch predictor, especially how the accuracy improvement came about, such as branch target buffer redesign, L1 B2B capacity doubling, L2 B2B reorganization, indirect target array (ITA) Increase, shorten the pipeline, reduce the delay of mispredictions, etc.
At the same time, the 32KB 8-way associated level 1 instruction cache has been optimized to improve the prefetch capability and utilization.
The operation cache is also more refined, the queue picking efficiency is higher, and the switching between the operation cache and the instruction cache pipeline is freer.
In terms of execution engine, the width of floating point and integer distribution is increased, FMAC delay is reduced, and the execution window is increased.
In terms of integer execution, the number of integer scheduler nodes has increased from 92 to 96 (4×24 distribution), and the number of physical register files used to rename logical registers to improve the efficiency of out-of-order execution has also increased from 180 to 192.
The distribution per clock cycle has also increased from 7 to 10, including 4 ALUs (arithmetic logic units), 3 AGUs (address generation units), 1 branch unit, and 2 storage data units.
In addition, the number of x86 instructions stored in the recorder buffer (ROB) has increased from 224 to 256.
The number of integer units in Zen 3 remains the same, but the ALU and AGU schedulers are shared, which is more balanced when dealing with different loads.
In terms of floating-point execution, the increase of the floating-point unit to 6 pipelines means that 6 micro-operation instructions can be dispatched at one time. At the same time, the MUL multiplication and ADD addition integer units responsible for storing and floating-point register files are now changed to independent pipelines. It can handle the real MUL and ADD instructions better.
There is also a faster 4-cycle FMAC, separate F2I and storage units, and a larger scheduler.
In terms of load/store, the number of storage queue nodes has been increased from 48 to 64, and the bandwidth between the 32KB L1 instruction cache has been increased, and 3 loads can be executed per clock cycle, or 2 floating point and 1 Storage, and also improved the prefetch algorithm to better utilize the triple-level cache that has doubled capacity.
Next, we return to the “advanced” level and take a look at Zen 3’s core and cache design.
This CDD core and cache layout diagram is familiar to everyone. Each CCD of Zen 2 and Zen 3 has 8 physical cores and 32MB L3 cache, but the former is two separate parts, each 4 cores share half of 16MB L3 cache, while the latter is a complete part, all 8 cores sharing all 32MB L3 cache is equivalent to directly doubling the available L3 cache capacity of each core.
On Zen 2, if the instructions and data required by a certain core are in the other half of the third-level cache that is not directly shared, then it must go around in a circle, and the delay will naturally increase greatly. Now it can be directly in place in one step. When the first core requires data is in the eighth core, it can also be quickly obtained directly inside CCX.
Look at the cache details. The first, second and third levels have not changed, but the efficiency is much higher. For example, the 32KB first-level instruction cache supports 32bit picking, the 32KB first-level data cache supports up to 3 loads and 2 stores, and the 512KB second level cache is faster.
After the capacity of the third-level cache is increased and the access is unified, the victim cache that is discarded in the second-level cache can be completely saved, which is equivalent to a backup, because they have a high probability of being accessed again, so no matter which core needs to be again, Can be obtained directly from the cache from the exchange.
In addition, each core allows 64 misses from the second-level cache to the third-level cache, and allows 192 misses from the third-level cache to the memory.
The Ryzen 5000 series continues the chipset design, one or two CCD Die with an IOD (in charge of the memory controller and input and output), but because each CCD has only one CCX instead of two independent, The connection and communication between CCD, IOD and memory are also more consistent and efficient.
When two CCDs are paired with an IOD, the bandwidth is the same, and the same consistency system.
At this time, it also reflects the benefits of chipset small chip design, which can easily achieve 16 cores, and can be upgraded to Zen 3 architecture without changing the layout and platform. Everything is done inside the package.
In terms of security, Zen 3 focuses on adding control flow enforcement technology (CET), which Intel has previously supported. It introduces the shadow stack, which only contains the return address and is stored in the system memory. At the same time, it is protected by the processor’s memory management module. If malicious code uses the vulnerability to change the stack, it can be found before causing harm and prevention can be done.
In terms of instruction set, AMD Zen 3 adds MPK, which is the memory protection key, which can be used to change data read and write permissions more efficiently by software. In addition, VAES and VPCLMULQD instructions add support for AVX2.
Finally, let’s talk about energy efficiency. According to the official statement, the Ryzen 9 5950X and Ryzen 9 5900X of the Zen 3 architecture are 2.8 times and 2.4 times that of the i9-10900K, respectively. Compared with the Zen 2 architecture, the AMD Ryzen 9 3950X and Ryzen 9 3900XT’s performance is also increased by 12% and 26% respectively.
Verdict – In short, AMD Zen 3 successfully achieved the expected goals, including a significant increase in IPC (19% on average), a significant reduction in latency (unified 8-core and 32MB L3 cache), a significant acceleration of memory access (direct access to the L3 cache doubled), and a significant increase in frequency (Maximum acceleration is 4.9GHz), energy efficiency is greatly improved (up to 2.8 times), and game frame rate is greatly increased, approximately 26% on average at 1080p.